 MENU
MENU 

Five papers by CSE researchers presented at NSDI
Researchers at U-M CSE have been accepted to present five papers at the 2020 Networked Systems Design and Implementation (NSDI) Conference, a top systems design conference. The students and faculty presented work on speeding up distributed computing, more efficient use of storage in distributed systems and datacenters, and preventing bugs in large services as they undergo updates.
Learn more about the papers:
 Enlarge
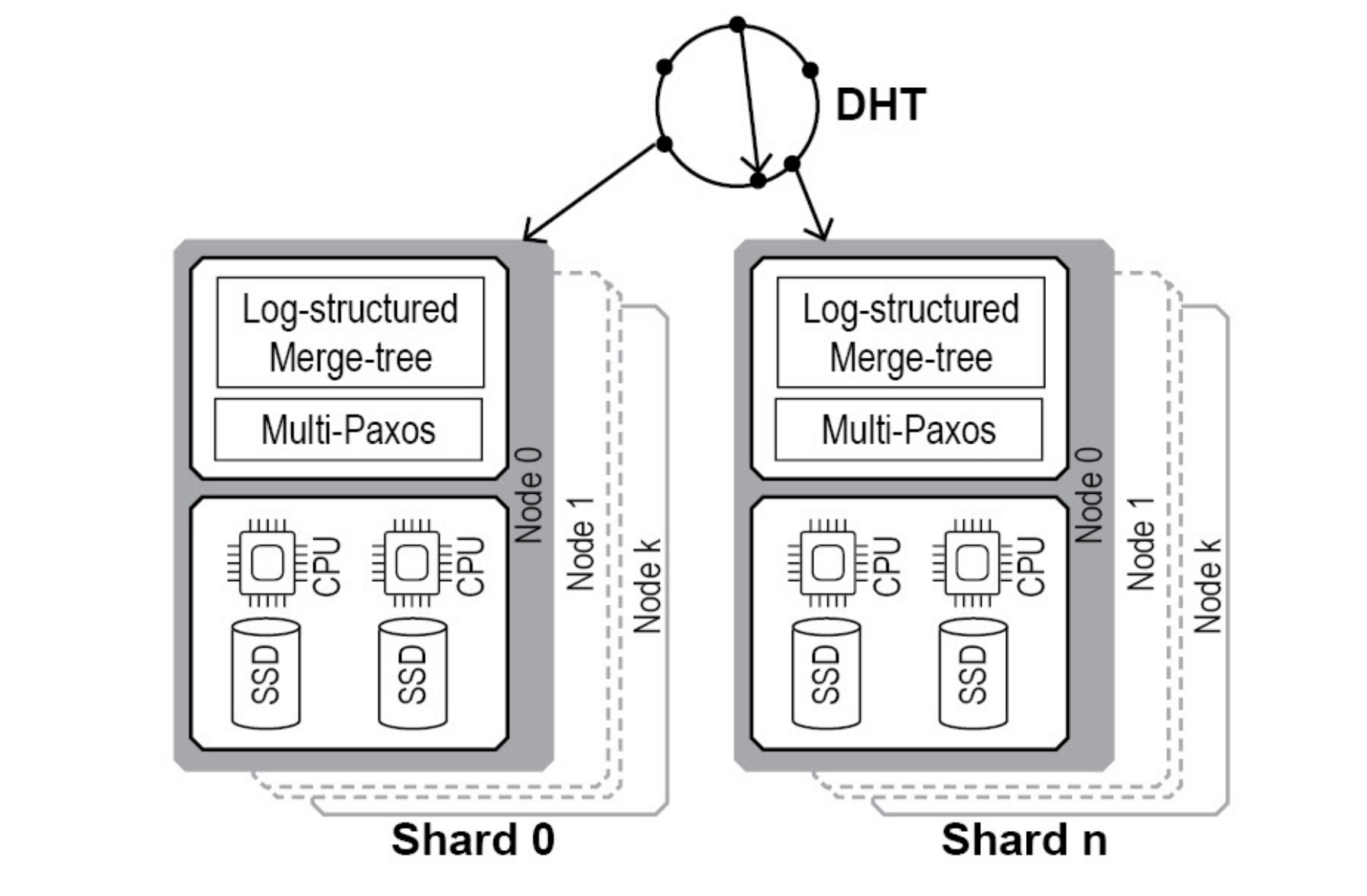
EnlargeFine-Grained Replicated State Machines for a Cluster Storage System
Ming Liu and Arvind Krishnamurthy, University of Washington; Harsha V. Madhyastha, University of Michigan; Rishi Bhardwaj, Karan Gupta, Chinmay Kamat, Huapeng Yuan, Aditya Jaltade, Roger Liao, Pavan Konka, and Anoop Jawahar, Nutanix
Enterprise clusters often rely on the abstraction of a block storage volume to support the virtualized execution of applications, appearing as local disks to the virtual machines running legacy applications. This paper describes the design and implementation of a consistent and fault-tolerant metadata index for a scalable block storage system. The researchers’ system supports the virtualized execution of legacy applications inside enterprise clusters by automatically distributing the stored blocks across the cluster’s storage resources. To support the availability and scalability needs of the block storage system, they developed a distributed index that provides a replicated and consistent key value storage abstraction.
 Enlarge
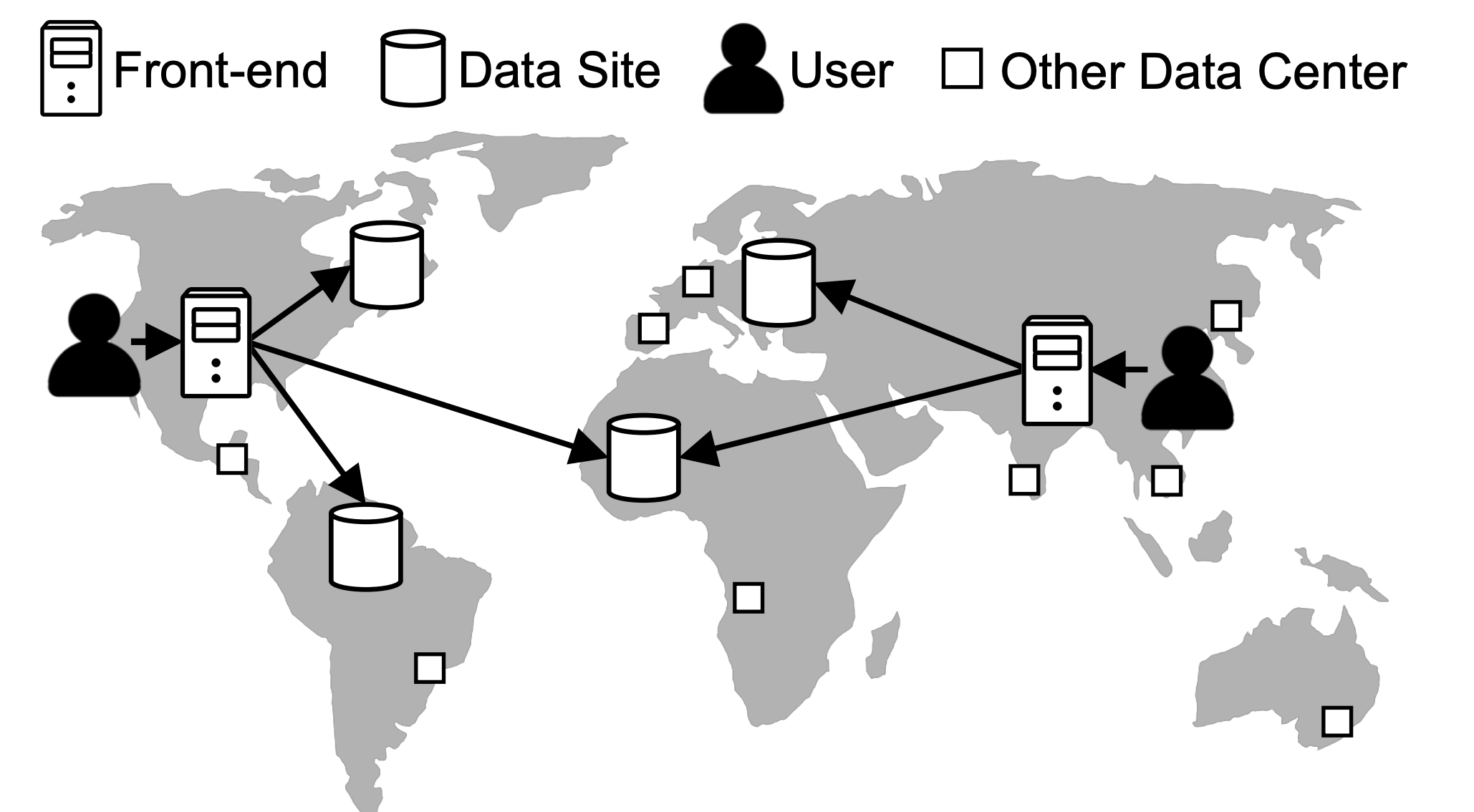
EnlargeNear-Optimal Latency Versus Cost Tradeoffs in Geo-Distributed Storage
Muhammed Uluyol, Anthony Huang, Ayush Goel, Mosharaf Chowdhury, and Harsha V. Madhyastha, University of Michigan
When multiple users spread around the world are sharing access to an application, like a shared online document, the underlying system needs to achieve several things: the version viewed by all users needs to be consistent, changes the users make can’t interfere with each other, and backup copies need to be saved to prevent loss of access from server interruptions, which all in turn have to be consistent and up to date. In addition, it all has to happen in the face of the latency that comes with globally distributed storage. This paper proposes a way to avoid making multiple copies of this shared data, using erasure coding of data across data centers instead of simple replication. Erasure coding works by storing redundant pieces of information in a way that allows recovery from complete storage device failures. To enable consistency on this new framework, the team then designed a new consistency protocol that can be applied on the encoded data.
 Enlarge
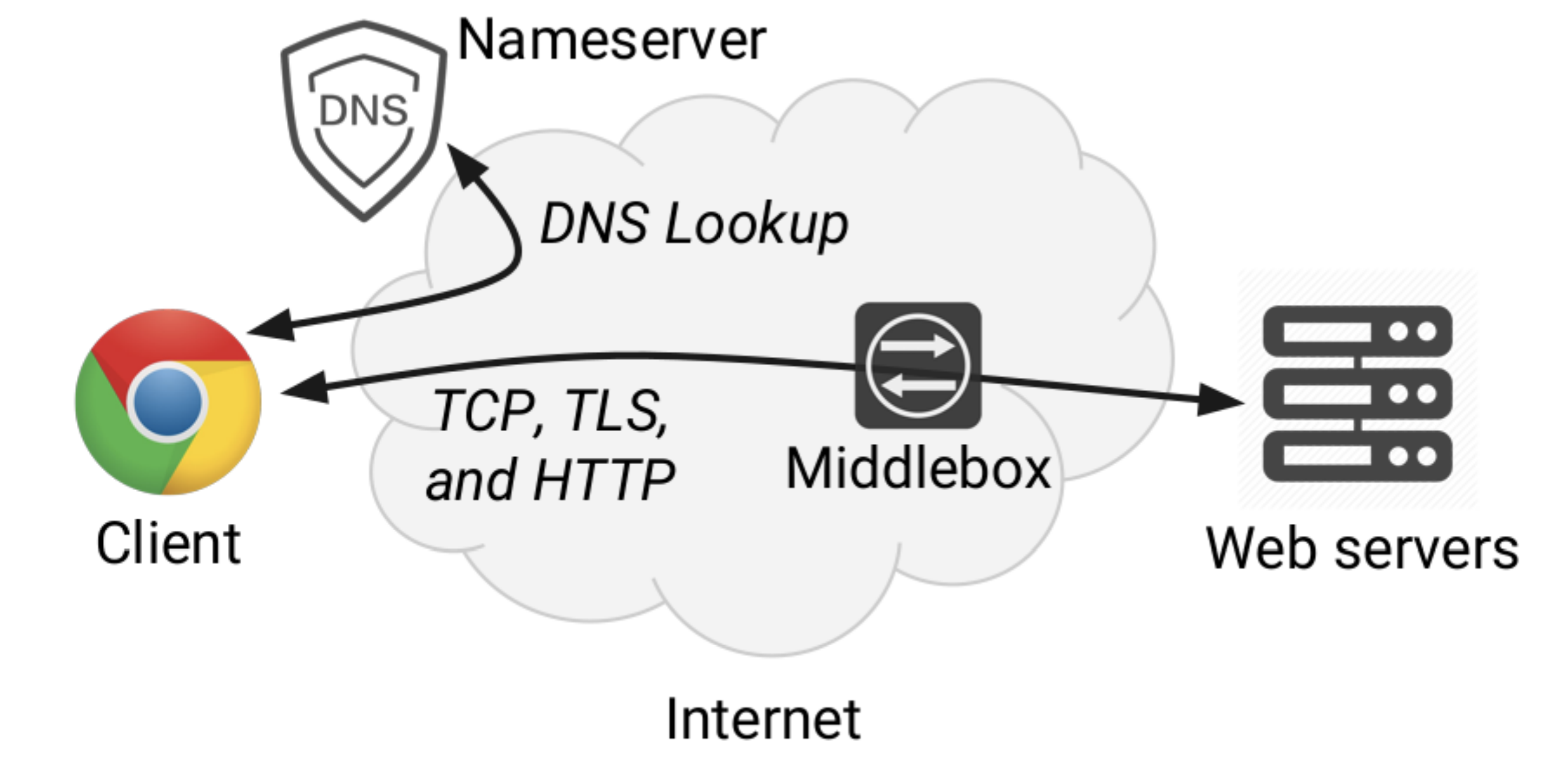
EnlargeNetwork Error Logging: Client-side measurement of end-to-end web service reliability
Sam Burnett and Lily Chen, Google; Douglas A. Creager, GitHub; Misha Efimov, Ilya Grigorik, and Ben Jones, Google; Harsha V. Madhyastha, Google and University of Michigan; Pavlos Papageorge, Brian Rogan, Charles Stahl, and Julia Tuttle, Google
This paper presents Network Error Logging (NEL), a planet-scale, client-side, network reliability measurement system. NEL is implemented in Google Chrome and has been proposed as a new W3C standard, letting any web site operator collect reports of clients’ successful and failed requests to their sites. These reports are similar to web server logs, but include information about failed requests that never reach serving infrastructure. Prof. Harsha Madhyastha worked on this project as part of a research team at Google.
 Enlarge
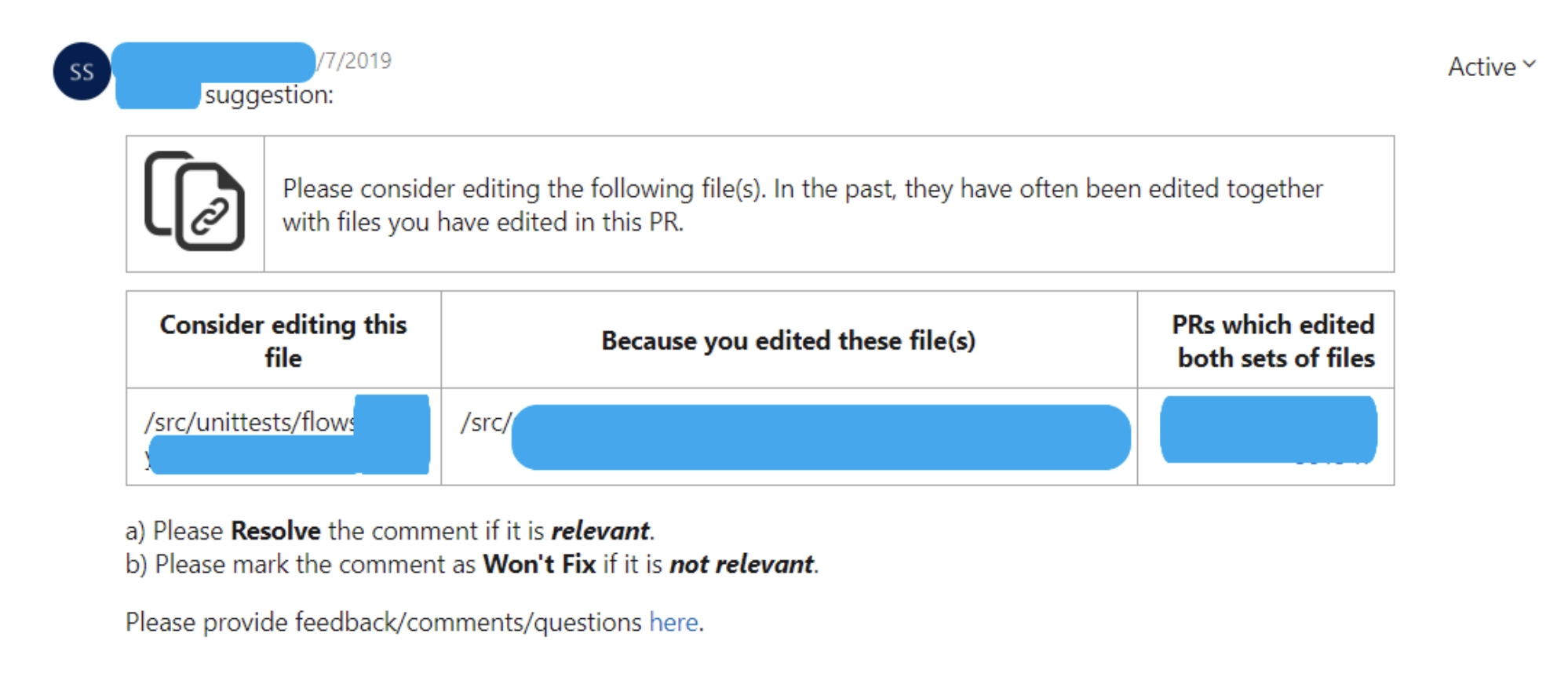
EnlargeRex: Preventing Misconfiguration and Bugs in Large Services Using Correlated Change Analysis
Sonu Mehta, Ranjita Bhagwan, and Rahul Kumar, Microsoft Research India; Chetan Bansal, Microsoft Research; Chandra Maddila and B. Ashok, Microsoft Research India; Sumit Asthana, University of Michigan; Christian Bird, Microsoft Research; Aditya Kumar
Large services experience extremely frequent changes to code and configuration. In many cases, these changes are correlated across files. Unfortunately, in almost all such cases, no documentation or specification guides engineers on how to make correlated changes and they often miss making them. Such misses can be vastly disruptive to the service. To address this, the research team designed and deployed Rex, a tool that, using a combination of machine learning and program analysis, learns change-rules that capture such correlations. When an engineer changes only a subset of files in a change-rule, Rex suggests additional changes to the engineer based on the change-rule. PhD student Sumit Asthana worked on this project as part of Microsoft Research, India.
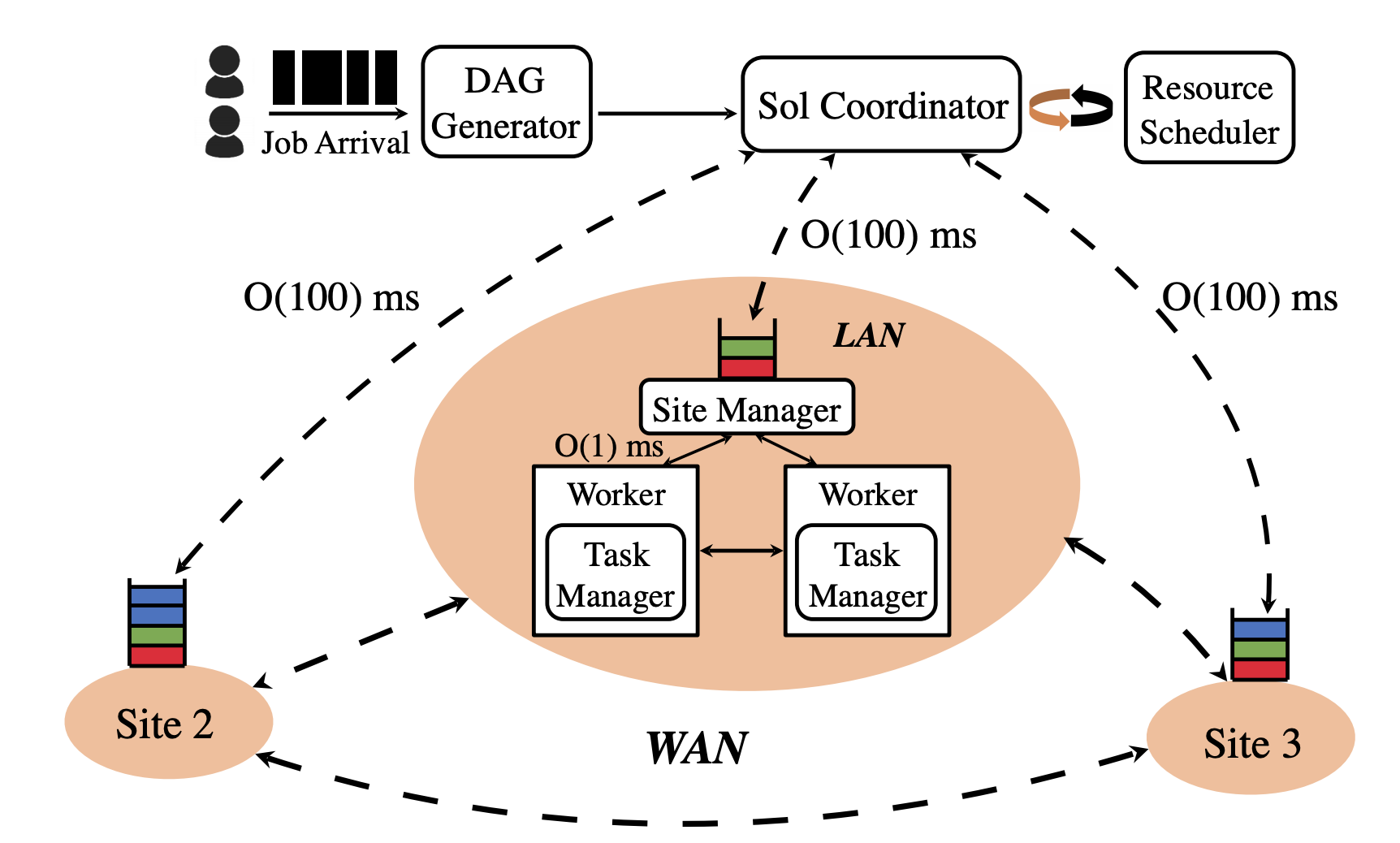 Enlarge
EnlargeSol: Fast Distributed Computation Over Slow Networks
Fan Lai, Jie You, Xiangfeng Zhu, Harsha V. Madhyastha, and Mosharaf Chowdhury, University of Michigan
The popularity of big data and AI has led to many optimizations at different layers of distributed computation stacks. But despite its important role in these stacks, the design of the execution engine, which is in charge of executing every single task of a job, has mostly remained unchanged. The engines in use are typically designed for high-bandwidth, low-latency datacenters, rather than the distributed computation that occurs now. This paper presents an approach to developing an execution engine that can adapt to diverse network conditions. Sol, the team’s federated execution engine architecture, takes two new approaches. First, to mitigate the impact of high latency, Sol proactively assigns tasks, but does so judiciously to be resilient to uncertainties. Second, to improve the overall resource utilization, Sol decouples communication from computation internally instead of committing resources to both aspects of a task simultaneously.