 MENU
MENU Six papers by CSE researchers at ICSE 2025
Six papers by authors affiliated with CSE are being presented at the 2025 IEEE/ACM International Conference on Software Engineering (ICSE), being held in Ottawa, Canada from April 27-May 3. The premier international conference in the area of software engineering, ICSE brings together researchers and practitioners from around the world to discuss the latest research results, innovations, trends, and challenges in the field.
New research by CSE authors at ICSE 2025 spans a range of topics related to software engineering, including bug discovery in the cloud, automated infrastructure management, support for programmers with ADHD, and more. The papers being presented are as follows, the names of authors affiliated with CSE in bold:
Towards a Cognitive Model of Dynamic Debugging: Does Identifier Construction Matter?
Danniell Hu, Priscila Santiesteban, Madeline Endres, Westley Weimer
Abstract: Debugging is a vital and time-consuming process in software engineering. Recently, researchers have begun using neuroimaging to understand the cognitive bases of programming tasks by measuring patterns of neural activity. While exciting, prior studies have only examined small sub-steps in isolation, such as comprehending a method without writing any code or writing a method from scratch without reading any already-existing code. We propose a simple multi-stage debugging model in which programmers transition between Task Comprehension, Fault Localization, Code Editing, Compiling, and Output Comprehension activities. We conduct a human study of n=28 participants using a combination of functional near-infrared spectroscopy and standard coding measurements (e.g., time taken, tests passed, etc.). Critically, we find that our proposed debugging stages are both neurally and behaviorally distinct. To the best of our knowledge, this is the first neurally-justified cognitive model of debugging. At the same time, there is significant interest in understanding how programmers from different backgrounds, such as those grappling with challenges in English prose comprehension, are impacted by code features when debugging. We use our cognitive model of debugging to investigate the role of one such feature: identifier construction. Specifically, we investigate how features of identifier construction impact neural activity while debugging by participants with and without reading difficulties. While we find significant differences in cognitive load as a function of morphology and expertise, we do not find significant differences in end-to-end programming outcomes (e.g., time, correctness, etc.). This nuanced result suggests that prior findings on the cognitive importance of identifier naming in isolated sub-steps may not generalize to end-to-end debugging. Finally, in a result relevant to broadening participation in computing, we find no behavioral outcome differences for participants with reading difficulties.

Automated Lifting for Cloud Infrastructure-as-Code Programs
Jingjia Peng, Yiming Qiu, Patrick Tser Jern Kon, Pinhan Zhao, Yibo Huang, Zheng Guo, Xinyu Wang, Ang Chen
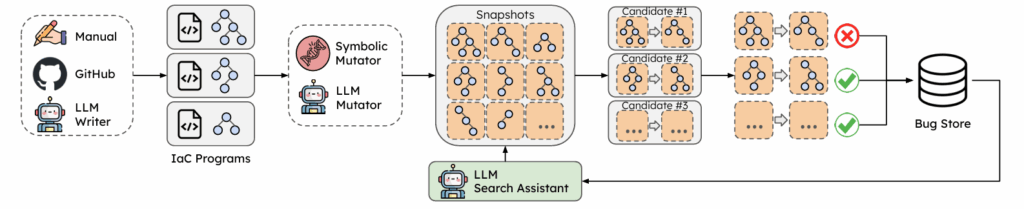
Abstract: Infrastructure-as-code (IaC) is reshaping how cloud resources are managed. IaC users write high-level programs to define their desired infrastructure, and the underlying IaC platforms automatically deploy the constituent resources into the cloud. While proven powerful at creating greenfield deployments (i.e., new cloud deployments from scratch), existing IaC platforms provide limited support for managing brownfield infrastructure (i.e., transplanting an existing non-IaC deployment to an IaC platform). This hampers the migration from legacy cloud management approaches to an IaC workflow and hinders wider IaC adoption. Managing brownfield deployments requires techniques to lift low-level cloud resource states and translate them into corresponding IaC programs —— the reversal of the regular deployment process. Existing tools rely heavily on rule-based reverse engineering, which suffers from the lack of automation, limited resource coverage, and prevalence of errors. In this work, we lay out a vision for Lilac, a new approach that frees IaC lifting from extensive manual engineering. Lilac brings the best of both worlds: leveraging Large Language Models to automate lifting rule extraction, coupled with symbolic methods to control the cloud environment and provide correctness assurance. We envision that Lilac would enable the construction of an automated and provider-agnostic lifting tool with high coverage and accuracy.
Automated Bug Discovery in Cloud Infrastructure-as-Code Updates with LLM Agents
Yiming Xiang, Zhenning Yang, Jingjia Peng, Hermann Bauer, Patrick Tser Jern Kon, Yiming Qiu, Ang Chen
Abstract: Cloud environments are increasingly managed by Infrastructure-as-Code (IaC) platforms (e.g., Terraform), which allow developers to define their desired infrastructure as a configuration program that describes cloud resources and their dependencies. This shields developers from low-level operations for creating and maintaining resources, since they are automatically performed by IaC platforms when compiling and deploying the configuration. However, while IaC platforms are rigorously tested for initial deployments, they exhibit myriad errors for runtime updates, e.g., adding/removing resources and dependencies. IaC updates are common because cloud infrastructures are long-lived but user requirements fluctuate over time. Unfortunately, our experience shows that updates often introduce subtle yet impactful bugs. The update logic in IaC frameworks is hard to test due to the vast and evolving search space, which includes diverse infrastructure setups and a wide range of provided resources with new ones frequently added. We introduce TerraFault, an automated, efficient, LLM-guided system for discovering update bugs, and report our findings with an initial prototype. TerraFault incorporates various optimizations to navigate the large search space efficiently and employs techniques to accelerate the testing process. Our prototype has successfully identified bugs even in simple IaC updates, showing early promise in systematically identifying update bugs in today’s IaC frameworks to increase their reliability.
A Controlled Experiment in Age and Gender Bias When Reading Technical Articles in Software Engineering
Anda Liang, Emerson Murphy-Hill, Westley Weimer, Yu Huang
Abstract: Online platforms and communities are a critical part of modern software engineering, yet are often affected by human biases. While previous studies investigated human biases and their potential harms against the efficiency and fairness of online communities, they have mainly focused on the open source and Q & A platforms, such as GitHub and Stack Overflow , but overlooked the audience-focused online platforms for delivering programming and SE-related technical articles, where millions of software engineering practitioners share, seek for, and learn from high-quality software engineering articles (i.e., technical articles for SE). Furthermore, most of the previous work has revealed gender and race bias, but we have little knowledge about the effect of age on software engineering practice. In this paper, we propose to investigate the effect of authors’ demographic information (gender and age) on the evaluation of technical articles on software engineering and potential behavioral differences among participants. We conducted a survey-based and controlled human study and collected responses from 540 participants to investigate developers’ evaluation of technical articles for software engineering. By controlling the gender and age of the author profiles of technical articles for SE, we found that raters tend to have more positive content depth evaluations for younger male authors when compared to older male authors and that male participants conduct technical article evaluations faster than female participants, consistent with prior study findings. Surprisingly, different from other software engineering evaluation activities (e.g., code review, pull request, etc.), we did not find a significant difference in the genders of authors on the evaluation outcome of technical articles in SE.
“Get Me In The Groove”: A Mixed Methods Study on Supporting ADHD Professional Programmers
Kaia Newman, Sarah Snay, Madeline Endres, Manasvi Parikh, Andrew Begel
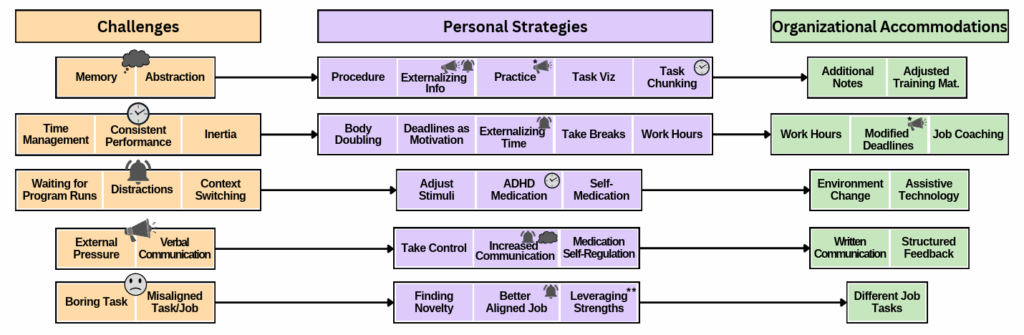
Abstract: Understanding the work styles of diverse programmers can help build inclusive workplaces, enabling all software engineers to excel. An estimated 10.6% of programmers have Attention Deficit Hyperactivity Disorder (ADHD), a condition characterized by differences in attention and working memory. Prior work has just begun to explore the impact of ADHD on software development, finding that inadequate support may negatively impact team productivity and employment. This prevents software development organizations from benefiting from ADHD-related strengths.
To investigate these impacts, we conducted a two-phase mixed methods study. First, we qualitatively analyzed 99 threads (1,658 posts and comments) from r/ADHD_Programmers, the largest public forum dedicated to the ADHD programmer community. We constructed a mapping that reveals how ADHD programmers apply personal strategies and organizational accommodations to address software task-specific challenges. Second, we conducted a large-scale survey of 239 ADHD and 254 non-ADHD professional programmers to validate how our qualitative data generalize to the worldwide developer population. Our results show that ADHD programmers are 1.8 to 4.4 times more likely to struggle more frequently than neurotypical developers with all challenges we consider, but especially with time management and design. Our findings have implications for inclusive and effective tool- and policy-building in software workplaces and motivate further research into the experiences of ADHD programmers.
Robust Testing for Deep Learning using Human Label Noise
Gordon Lim, Stefan Larson, Kevin Leach
Abstract: In deep learning (DL) systems, label noise in training datasets often degrades model performance, as models may learn incorrect patterns from mislabeled data. The area of Learning with Noisy Labels (LNL) has introduced methods to effectively train DL models in the presence of noisily-labeled datasets. Traditionally, these methods are tested using synthetic label noise, where ground truth labels are randomly (and automatically) flipped. However, recent findings highlight that models perform substantially worse under human label noise than synthetic label noise, indicating a need for more realistic test scenarios that reflect noise introduced due to imperfect human labeling. This underscores the need for generating realistic noisy labels that simulate human label noise, enabling rigorous testing of deep neural networks without the need to collect new human-labeled datasets. To address this gap, we present Cluster-Based Noise (CBN), a method for generating feature-dependent noise that simulates human-like label noise. Using insights from our case study of label memorization in the CIFAR-10N dataset, we design CBN to create more realistic tests for evaluating LNL methods. Our experiments demonstrate that current LNL methods perform worse when tested using CBN, highlighting its use as a rigorous approach to testing neural networks. Next, we propose Soft Neighbor Label Sampling (SNLS), a method designed to handle CBN, demonstrating its improvement over existing techniques in tackling this more challenging type of noise.