 MENU
MENU Michigan and ECE advancing computer vision at CVPR 2023
Computer vision has evolved to the point where it has been described as the “backbone of an autonomous future.” Advancements in the field are being presented June 20-22, 2023 at CVPR 2023, the IEEE/CVF Conference on Computer Vision and Pattern Recognition, widely considered to be one of the most important in the field. More than 20 papers being presented at CVPR 2023 are by faculty and researchers affiliated with the University of Michigan. Eight of those papers represent the work of ECE faculty members Jason Corso, Hun-Seok Kim, and Andrew Owens, as well as current or former students.
The ECE research being presented shows ways to detect when one image has been spliced into another, or when a video contains manipulated speech. It also presents a way to improve robot navigation when given verbal cues, an improved method for compressing videos, and more.
Following are the papers representing ECE-affiliated research. The names in bold are all affiliated with the University of Michigan. The first two papers were selected as a Conference Highlight, an honor given to 10% of the accepted papers.
EXIF As Language: Learning Cross-Modal Associations Between Images and Camera Metadata [Conference Highlight]
Chenhao Zheng, Ayush Shrivastava, Andrew Owens

Abstract: In this paper, we learn visual representations that convey camera properties by creating a joint embedding between image patches and photo metadata. This model treats metadata as a language-like modality: it converts EXIF tags that compose the metadata into a long piece of text, and processes it using an off-the-shelf model from natural language processing. We demonstrate the effectiveness of our learned features on a variety of downstream tasks that require an understanding of low-level imaging properties, where it outperforms other feature representations. In particular, we successfully apply our model to the problem of detecting image splices “zero shot” by clustering the crossmodal embeddings within an image.
Self-Supervised Video Forensics by Audio-Visual Anomaly Detection [Conference Highlight]
Chao Feng, Ziyang Chen, Andrew Owens
Abstract: Manipulated videos often contain subtle inconsistencies between their visual and audio signals. We propose a video forensics method, based on anomaly detection, that can identify these inconsistencies, and that can be trained solely using real, unlabeled data. We train an autoregressive model to generate sequences of audio-visual features, using feature sets that capture the temporal synchronization between video frames and sound. At test time, we then flag videos that the model assigns low probability. Despite being trained entirely on real videos, our model obtains strong performance on the task of detecting manipulated speech videos.
Iterative Vision-and-Language Navigation
Jacob Krantz, Shurjo Banerjee, Wang Zhu, Jason Corso, Peter Anderson, Stefan Lee, Jesse Thomason.
Abstract: We present Iterative Vision-and-Language Navigation (IVLN), a paradigm for evaluating language-guided agents navigating in a persistent environment over time. Existing Vision-and-Language Navigation (VLN) benchmarks erase the agent’s memory at the beginning of every episode, testing the ability to perform cold-start navigation with no prior information. However, deployed robots occupy the same environment for long periods of time. The IVLN paradigm addresses this disparity by training and evaluating VLN agents that maintain memory across tours of scenes that consist of up to 100 ordered instruction-following Room-to-Room (R2R) episodes, each defined by an individual language instruction and a target path. We present discrete and continuous Iterative Room-to-Room (IR2R) benchmarks comprising about 400 tours each in 80 indoor scenes. We find that extending the implicit memory of high-performing transformer VLN agents is not sufficient for IVLN, but agents that build maps can benefit from environment persistence, motivating a renewed focus on map-building agents in VLN.
GANmouflage: 3D Object Nondetection with Texture Fields
Rui Guo, Jasmine Collins, Oscar de Lima, Andrew Owens

Abstract: We propose a method that learns to camouflage 3D objects within scenes. Given an object’s shape and a distribution of viewpoints from which it will be seen, we estimate a texture that will make it difficult to detect. Successfully solving this task requires a model that can accurately reproduce textures from the scene, while simultaneously dealing with the highly conflicting constraints imposed by each viewpoint. We address these challenges with a model based on texture fields and adversarial learning. Our model learns to camouflage a variety of object shapes from randomly sampled locations and viewpoints within the input scene. It is also the first to address the problem of hiding complex object shapes. Using a human visual search study, we find that our estimated textures conceal objects significantly better than previous methods.
Bowen Liu, Yu Chen, Rakesh Chowdary Machineni, Shiyu Liu, Hun-Seok Kim

Abstract: Learning-based video compression has been extensively studied over the past years, but it still has limitations in adapting to various motion patterns and entropy models. In this paper, we propose multi-mode video compression (MMVC), a block wise mode ensemble deep video compression framework that selects the optimal mode for feature domain prediction adapting to different motion patterns. Proposed multi-modes include ConvLSTM-based feature domain prediction, optical flow conditioned feature domain prediction, and feature propagation to address a wide range of cases from static scenes without apparent motions to dynamic scenes with a moving camera. We partition the feature space into blocks for temporal prediction in spatial block-based representations. For entropy coding, we consider both dense and sparse post-quantization residual blocks, and apply optional run-length coding to sparse residuals to improve the compression rate. In this sense, our method uses a dual-mode entropy coding scheme guided by a binary density map, which offers significant rate reduction surpassing the extra cost of transmitting the binary selection map. We validate our scheme with some of the most popular benchmarking datasets. Compared with state-of the-art video compression schemes and standard codecs, our method yields better or competitive results measured with PSNR and MS-SSIM.
Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment
Kim Sung-Bin, Arda Senocak, Hyunwoo Ha, Andrew Owens, Tae-Hyun Oh
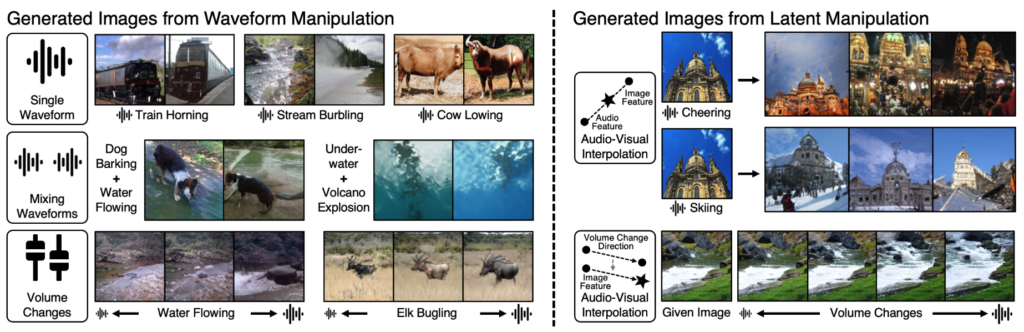
Abstract: How does audio describe the world around us? In this paper, we explore the task of generating an image of the visual scenery that sound comes from. However, this task has inherent challenges, such as a significant modality gap between audio and visual signals, and audio lacks explicit visual information inside. We propose Sound2Scene, a model that works by scheduling the learning procedure of each model component to associate audio-visual modalities despite their information gaps. The key idea is to enrich the audio features with visual information by learning to align audio to visual latent space. Thereby, we translate input audio to visual feature, followed by a powerful pre-trained generator to generate an image. We further incorporate a highly correlated audio-visual pair selection method to stabilize the training. As a result, our method demonstrates substantially better quality in a large number of categories on VEGAS and VGGSound datasets, compared to the prior arts of sound-to-image generation. Besides, we show the spontaneously learned output controllability of our method by applying simple manipulations on the input in the waveform space or latent space.
Conditional Generation of Audio From Video via Foley Analogies
Yuexi Du, Ziyang Chen, Justin Salamon, Bryan Russell, Andrew Owens

Abstract: The sound effects that designers add to videos are designed to convey a particular artistic effect and, thus, may be quite different from a scene’s true sound. Inspired by the challenges of creating a soundtrack for a video that differs from its true sound, but that nonetheless matches the actions occurring on screen, we propose the problem of conditional Foley. We present the following contributions to address this problem. First, we propose a pretext task for training our model to predict sound for an input video clip using a conditional audio-visual clip sampled from another time within the same source video. Second, we propose a model for generating a soundtrack for a silent input video, given a user-supplied example that specifies what the video should “sound like”. We show through human studies and automated evaluation metrics that our model successfully generates sound from video, while varying its output according to the content of a supplied example.
PyPose: A Library for Robot Learning With Physics-Based Optimization
Chen Wang, Dasong Gao, Kuan Xu, Junyi Geng, Yaoyu Hu, Yuheng Qiu, Bowen Li, Fan Yang, Brady Moon, Abhinav Pandey, Aryan, Jiahe Xu, Tianhao Wu, Haonan He, Daning Huang, Zhongqiang Ren, Shibo Zhao, Taimeng Fu, Pranay Reddy, Xiao Lin, Wenshan Wang, Jingnan Shi, Rajat Talak, Kun Cao, Yi Du, Han Wang, Huai Yu, Shanzhao Wang, Siyu Chen, Ananth Kashyap, Rohan Bandaru, Karthik Dantu, Jiajun Wu, Lihua Xie, Luca Carlone, Marco Hutter, Sebastian Scherer
Description: The link above is to a website that will allow anyone to install PyPose, developed to connect classic robotics with modern learning methods seamlessly. PyPose is designed for robotic applications including SLAM (VIO, stereo VO, multiple view VO, LiDAR), Control (MPC), and Planning. It can combine geometry-based methods such as bundle adjustments and factor graph optimization with learning-based methods such as feature extraction and loop closure detection.
Michigan Research outside of ECE at CVPR
In addition to the papers from ECE-affiliated faculty, Michigan researchers from CSE, Robotics, Naval and Marine Engineering, and Mechanical Engineering are also being presented. Refer to this article for information about the CSE papers. Following are additional papers:
E2PN: Efficient SE(3)-Equivariant Point Network Poster Session
Minghan Zhu, Maani Ghaffari, William A. Clark, Huei Peng
Description: E2PN is a SE(3)-equivariant network architecture designed for deep point cloud analysis. It largely improves the efficiency in terms of memory consumption and running speed for equivariant point cloud feature learning.
Hyperspherical Embedding for Point Cloud Completion Poster Session
Junming Zhang, Haomeng Zhang, Ram Vasudevan, Matthew Johnson-Roberson
Abstract: Most real-world 3D measurements from depth sensors are incomplete, and to address this issue the point cloud completion task aims to predict the complete shapes of objects from partial observations. Experiment results show consistent improvement of point cloud completion in both single-task and multi-task learning, which demonstrates the effectiveness of the proposed method.