 MENU
MENU 

Tool for structuring data creates efficiency for data scientists
Foofah is a tool that can help to minimize the effort and required background knowledge needed to clean up data.
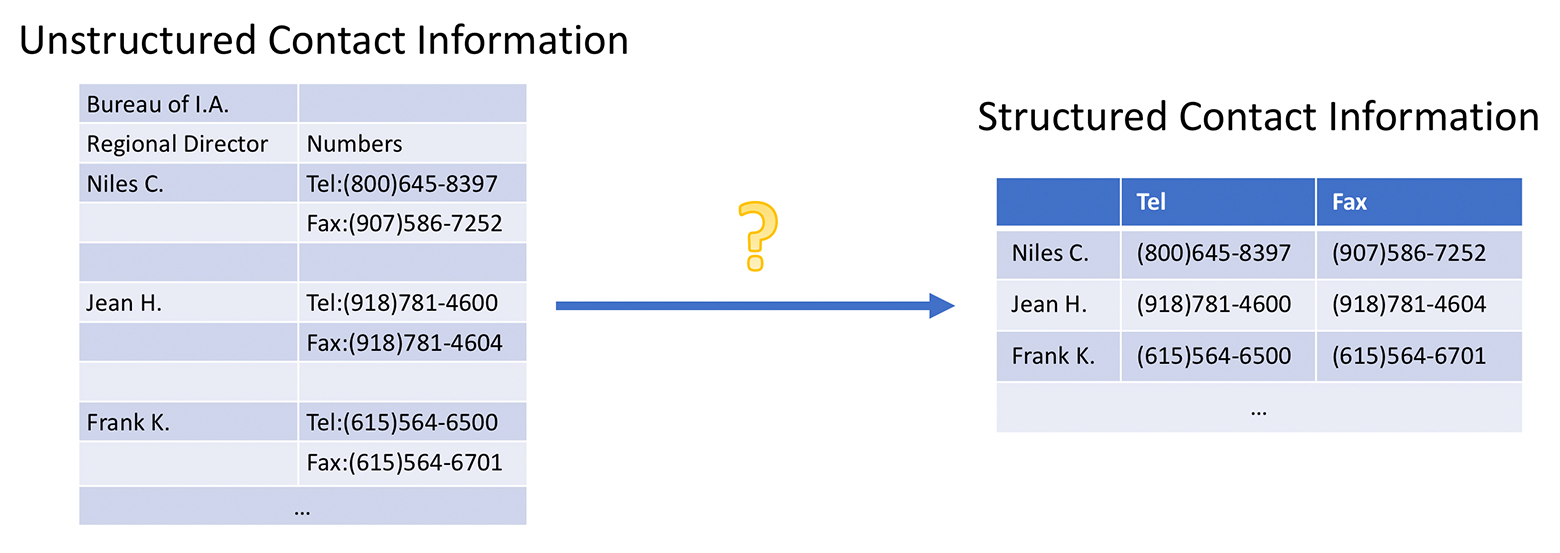
The life of a data scientist isn’t all analysis and conclusions – in fact, that’s not even half of it in most fields. Much of the world’s data is messy, unstructured, and therefore unusable. Because of this, scientists usually have to spend far more time preparing their data than they do analyzing it. Sometimes tidying up datasets can take up 80% of their time.
Transforming this data into a usable state turns out to be labor-intensive and tedious. Traditionally, domain experts handwrite task-specific scripts to transform unstructured data. The requirement for programming hamstrings data users that are capable analysts but have limited coding skills. Even worse, these scripts are tailored to particular data sources and cannot adapt when new sources are acquired.
 Enlarge
Enlarge Enlarge
EnlargeEnter Foofah, a project developed by CSE graduate students Zhongjun Jinand Michael Anderson, Prof. Michael Cafarella, and Bernard A. Galler Collegiate Professor of Electrical Engineering and Computer Science H.V. Jagadish that can help to minimize the effort and required background knowledge needed to clean up data. Their solution uses a technique called Programming-By-Example (PBE), requiring only before and after examples to generate transformation operations automatically.
In most typical data transformation programs, the user is required to select and order different operations to get their data from its messy state to the finished product. This means they have to know what each operation does, and logic their way through the effects each one would have on their dataset.
With a PBE approach, the user just has to know what they want the data to look like when it’s finished. They manually clean up one or two examples, feed that to the program, and the operations are selected automatically. Foofah searches the space of possible operations to generate a program that will perform the transformation.
The team held experiments to test just how straightforward their solution was. They invited ten CSE graduate students with no experience in data transformation to participate in a user study, and measured the time each of them took to complete eight different tasks using Foofah and a major industry standard tool called Data Wrangler.
In half of their experiments, Foofah required only one input-output example to pass the benchmark tests, and only two in another 40%. The tests found that it requires about 60% less user effort than Data Wrangler, and its average runtime is only 1.4 seconds. On one lengthy and complex test case, 4 out of 5 test takers could not find a solution within 10 minutes using Wrangler, but all of them found a solution within 3 minutes using Foofah.
This project was selected as “best of demos” and was chosen to present in a special session in SIGMOD 2017. The paper is titled “Foofah: Transforming Data By Example.”